

A well-constructed data pipeline is a powerful tool that streamlines your ability to process and analyze information efficiently, transforming raw data into actionable insights.
Think of it as your business's central nervous system. Your data pipeline automates the transport and refining of data, which means less manual work and more accuracy in the insights you generate. With a robust data pipeline, you're no longer swimming in an ocean of data with no direction. Instead, you've got a map and a motorboat, empowering you to navigate the vast data seas with purpose and precision.
Increased Efficiency and Scalability:
- Automated processes reduce time-consuming data tasks
- Scalability to handle growing data volumes without compromising performance
Leveraging a data pipeline doesn't just save you time; it also ensures that the information you base your decisions on is as current as possible. Data freshness is vital, and a stale data set could lead to outdated strategies that no longer resonate with your market.
Adding to the real-time aspect, consider data quality. Your pipeline acts as a filter, removing the impurities and inconsistencies that can lead data-driven decisions astray. High-quality data is integral to predictive analytics and machine learning algorithms, both of which can dramatically improve your operational efficiency and customer experience.
- Secure data transfer protocols safeguard sensitive information
- Compliance with regulations like GDPR made more manageable
By establishing a data pipeline, you're also ensuring compliance and security. As data moves through the pipeline, it can be encrypted and monitored, reducing the risk of breaches that could damage your reputation and bottom line.
Understanding the components of a data pipeline
A solid pipeline relies on several key components that work together to move your data smoothly from source to destination.
At its start, you have data sources. These can be databases, CSV files, live feeds, or any repository that holds the raw data you'll need. It's where your data journey begins.
The next component is data ingestion. This process is where data is imported, transferred, loaded, or otherwise brought into the system. Tools like Apache NiFi or Amazon Kinesis can make managing this flow a breeze.
Following ingestion, the data storage phase begins. This may involve temporary storage in a data lake or long-term storage in a data warehouse. The choice here impacts your data's accessibility and the cost of your pipeline.
Data processing then takes the stage. Whether by batch processing or real-time streaming, here's where data is transformed and readied for analysis. You could use Apache Spark for batch jobs or Storm for processing streams.
Then, you've got data orchestration which coordinates the workflow of the datasets across the pipeline. Apache Airflow is a popular tool that helps in creating, scheduling, and monitoring workflows.
Finally, data monitoring and management ensures the flow remains operational and efficient. You need to track the health of your pipeline and guarantee data quality throughout. Implementing robust monitoring is imperative for identifying and resolving issues quickly.
Your entire pipeline must be designed with security and compliance considerations in mind, safeguarding sensitive information and meeting regulatory requirements.
Remember, efficient data pipelines are a competitive advantage in today's data-driven world. Employ the right tools and practices to keep your pipeline's components working in harmony.
Choosing the right tools for your data pipeline
When setting out to construct your business's data pipeline, selecting the right tools becomes instrumental. You're searching for the perfect balance of scalability, efficiency, and compatibility.
Data Ingestion Tools are your first hurdle. They're the entry points for your data, ranging from high-velocity streams to batch uploads. If your business demands instantaneous data handling, look for solutions that offer real-time processing capabilities like Apache Kafka or Amazon Kinesis.
For Data Storage, you'd want robust and scalable systems. Choices like Amazon S3 and Google Cloud Storage are popular due to their reliability and ease of integration. With data lakes, warehouses, and databases, often SQL for structured data and NoSQL for unstructured data come into play.
Moving towards Data Processing, tools like Apache Spark and Apache Flink are household names for a reason. They offer lightning-fast distributed processing, handling colossal datasets with ease.
Data Orchestration requires choreographing complex workflows and dependencies. Apache Airflow stands out, allowing you to program, schedule, and monitor your pipelines with a user-friendly interface.
Finally, when you move to Data Monitoring and Management, you might consider platforms like DataDog or Prometheus. These tools provide oversight and alerts to ensure your pipeline operates smoothly.
Here are the core stages and a recommended toolset for building a data pipeline:
Assess each tool's integration capability with your existing systems. Your goal is to build a cohesive, seamless infrastructure. Also, ensure the tools align with your team's skills – a consideration as crucial as the technical requirements.
To further refine your selection, peer reviews can be incredibly helpful. Websites like Gartner provide in-depth analyses and reviews of data management software by professionals who've tackled similar challenges.
Designing and architecting your data pipeline
Your first step is to map out the data flow. It's critical to understand where your data originates, how it moves through the system, and where it ends up. Start by identifying your data sources, whether they're internal databases, SaaS applications, or external APIs.
Here's a simple outline of how to approach this process:
- Identify data sources: List all the potential sources where data is generated, including user interactions, transaction records, or external data feeds.
- Establish data endpoints: Determine where the processed data will be used, whether it's for analytics, machine learning models, or business intelligence reports.
- Define transformation requirements: Clarify what data manipulation or enrichment is needed to make the data useful for your goals.
With these details in hand, select an architecture that supports robust data movement and transformation. You might opt for a traditional ETL (Extract, Transform, Load) process or consider a more modern data pipeline approach, such as ELT (Extract, Load, Transform), where transformation happens after loading data into a data warehouse.
Considering your tech stack compatibility is crucial to avoid integration headaches down the road. Look for platforms that offer managed services for data pipelines, which can significantly reduce the operational overhead and ensure you have professional support when needed.
As you architect your pipeline, security, and compliance cannot be an afterthought. Carry out security protocols and access controls from the start. Ensure that any tools or platforms you choose comply with standards like GDPR if you're handling European customers' data.
Test your architecture thoroughly. Simulate data flow scenarios to gauge performance and identify potential bottlenecks. Testing should go beyond functional verification; it's about ensuring your pipeline can handle the volume and velocity of data typical to e-commerce.
Remember, as your business scales, your data pipeline should flexibly scale. A well-architected pipeline allows for easy scalability and adjustment over time, making future expansions or modifications less disruptive to your operations.
Implementing and testing your data pipeline
Once you've designed a custom-built data pipeline for your business needs, the next step is implementation. You'll want to start by setting up the infrastructure that supports the flow and storage of your data. This could involve configuring cloud services, databases, and any required on-premise resources. Key considerations should include reliability, throughput, and latency to ensure the pipelines meet performance benchmarks.
After your infrastructure is in place, you'll carry out the processes that will move data along the pipeline. This involves coding the logic for data extraction, transformation, and loading (ETL). It's here that you'll integrate various tools and platforms, such as Apache NiFi or Talend, which can streamline the ETL processes. Also, you'll need to write scripts or set up off-the-shelf solutions for automated data cleaning and validation to maintain data integrity.
Testing is an essential phase that comes right after implementation. Unit testing and integration testing will help catch any issues early in the development process. But you can't overlook performance and load testing when it comes to data pipelines. These tests ensure that your pipeline runs smoothly under realistic conditions and volumes of data. You'll want to simulate different scenarios to see how your pipeline behaves with varying data loads and velocities.
For practical examples and deeper insights into performance testing methodologies, reference material from Microsoft's ETL Documentation provides in-depth guidance.
- Create unit and integration tests.
- Perform load testing.
- Simulate realistic operating conditions.
The data governance aspect takes center stage now. Ensuring that your pipeline adheres to relevant data protection regulations such as GDPR or CCPA is crucial. This requires implementing proper authentication, authorization, encryption, and regular audits.
As you monitor the pipeline's performance, look for areas of improvement. You might find opportunities to optimize data processing or storage costs. This ongoing optimization process is crucial to keep the pipeline efficient and cost-effective.
Monitoring and maintaining your data pipeline
To ensure your data pipeline's long-term success, it's essential to understand the importance of monitoring and maintenance. Initiating comprehensive monitoring processes allows you to proactively track your pipeline's performance and health. You're not just looking for bugs; you're also watching for system inefficiencies, potential data losses, or bottlenecks that could drag your platform down.
Start with real-time monitoring systems that give insights into every aspect of the data pipeline. Tools like Prometheus and Grafana are superb for visualizing performance metrics, whereas Apache Airflow can manage your pipelines with built-in monitoring features.
Monitoring these systems provides actionable data that can help you pre-empt serious issues.
For the maintenance side, you'll want to focus on regular updates and scheduled maintenance activities. This could range from updating software to keep in line with the latest security protocols to reevaluating performance tuning parameters.
Here's a quick look at what your maintenance checklist might include:
- Update security measures regularly
- Optimize performance settings
- Scale resources as needed
- Validate data quality and consistency
Adopt a solid strategy for incident management and resolution. Should an issue arise, having a methodical approach can mean the difference between a minor hiccup and a full-blown outage. Having a plan in place for such scenarios will ensure rapid problem identification and swift resolution.
Enhance your pipeline's resilience by implementing automated testing and rollbacks. Automation can quickly detect when something is amiss, and orchestrated rollbacks can revert your systems to a last-known good configuration without manual intervention.
Remember, a pipeline isn't just set up once; it's a dynamic system that needs ongoing attention. Keeping abreast of the latest advancements in data pipeline technology can provide opportunities for improvement. Resources like the Data Engineering Weekly newsletter can be a great way to stay updated on industry trends and best practices.
Backup and recovery protocols cannot be understated. Regularly test your backups to ensure they're functioning correctly and that you can restore operations swiftly in case of data corruption or loss.
In the end, your diligence in monitoring and maintaining your data pipeline safeguards not only the data itself but also the integrity of the business decisions that data informs. Embrace the upkeep of your pipeline, and you'll sustain a robust backbone for your business intelligence efforts.
Conclusion
As you would have known by now, building and maintaining a robust data pipeline is crucial to your business's success. You've seen the importance of diligent monitoring, regular updates, and a proactive approach to incident management. Remember, it's not just about setting up the pipeline but also about ensuring it runs smoothly and efficiently.
Staying abreast of industry trends and having solid backup and recovery protocols in place will safeguard your operations against unforeseen events. With these practices, you'll keep your data flowing and your business thriving.
Looking to do more with your data?
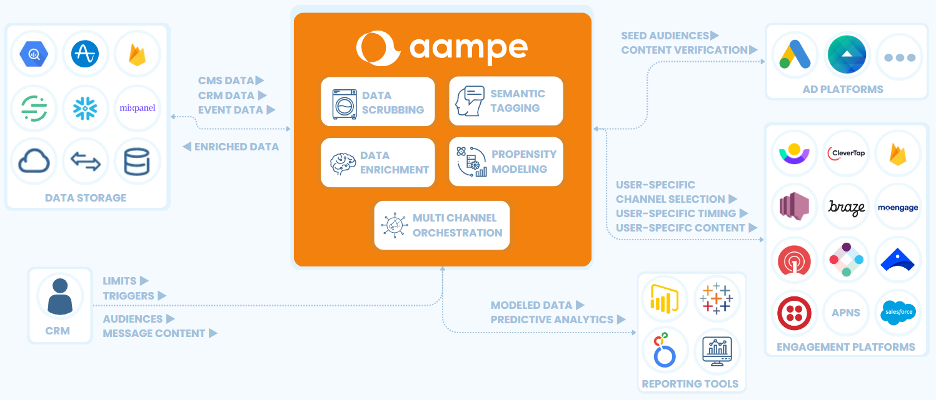
Aampe helps teams use their data more effectively, turning vast volumes of unstructured data into effective multi-channel user engagement strategies. Click the big orange button below to learn more!



.png)


