
System Purpose
Aampe's agentic AI infrastructure allows our customers to provision and manage an agent for every one of their end-users. If you're a food delivery app with 10 million customers, deploying Aampe lets you provision and manage 10 million agents.
While Aampe's agent design enables them to operate a lot of causal learning, experimentation, attribution, and optimization methods, agents are ultimately still just tools or employees of human teams. Human teams need to be able to provide their agents with creative ideas, with business knowledge or exogenous information as context to the agents' decisions and learning processes.
While natural language is an incredible general human technology, for specific instructions that can be precisely defined and rigorously tracked and audited, natural language can be an inferior interface. As part of our management layer over our agentic infrastructure, we needed to develop a more classic structured interface that would enable humans to identify very precise characteristics of a hypothetical user or group of users. Agents then can learn over those characteristics and develop effective communication and experience interventions for those characteristics. The rest of this post describes the capability we've developed.
System Overview
This post describes a real-time audience analytics platform that processes millions of events daily while maintaining sub-second query performance for complex eligible user building logic. This technical deep-dive explores our complete system architecture: from ClickHouse’s native JSON storage optimization to our sophisticated query engine that translates JSON Logic expressions into highly optimized SQL.
Our platform serves marketing teams who need to precisely identify user characteristics in real-time based on:
Complex behavioral patterns (event counts)
Dynamic user attributes (demographics, preferences, computed traits)
Cross-dimensional analysis (combining events + traits with logical operators)
Time-sensitive queries (within-last operations, date ranges, cohort analysis)
Our query engine supports 30 different operators for complex logic building
Core System Architecture
High-Level Components
Multi-Table Architecture Design
Our ClickHouse architecture uses three specialized tables optimized for different access patterns:
1. User Events (Behavioral Data)
Design Rationale:
ReplacingMergeTree: Automatic deduplication of duplicate events
Weekly Partitioning: Reduces partition count by 7x, faster date range queries
Native JSON: Type-aware storage with automatic schema inference
Delta Compression: 80% space reduction for timestamp columns
Optimal Sort Key: Enables PREWHERE optimization for event filtering
2. User Properties (User State)
Design Rationale:
Single Row Per User: Latest state snapshot for O(1) lookups and for total users count
Hybrid Storage: JSON for flexible attributes + added Aampe native attribute columns (not shown in the the schema)
Direct Columns: 10x faster access for frequently queried computed traits
ZSTD Compression: 70% storage reduction for JSON properties
3. User Attributes (Normalized Key-Value)
Design Rationale:
Normalized Storage: Efficient indexing and filtering on attribute keys
Key-First Ordering: Enables rapid filtering by attribute type
String Values: Flexible storage with runtime type casting
Materialized View Sync: Auto-populated from JSON properties
ClickHouse Native JSON Type - Deep Dive
How JSON Type Works Internally
ClickHouse’s new JSON type (introduced in version 23.x) revolutionizes semi-structured data storage. Unlike storing JSON as String or using Map types, the native JSON type provides:

Storage Optimization:
Columnar Storage: Each JSON path becomes a virtual column
Type-Specific Compression: Numbers vs strings compressed differently
Null Handling: Missing paths consume zero storage
Schema Evolution: New paths added without migration
New Dynamic Type: Clickhouse stores unknown types as Dynamic columns which can hold a bunch of types together
JSON Type Configuration and Performance
Optimal Configuration:
Automatic Type Inference and Storage
ClickHouse’s JSON type provides sophisticated type inference:
JSON Type Performance Characteristics

Known Issues with JSON Type in ClickHouse
No direct indexing on JSON values - Cannot create bloom filter or minmax indexes unless structure is known beforehand
Cannot ORDER BY JSON keys/values - Prevents PREWHERE optimizations for queries like
json.key = 'value'Slower than regular columns - Involves disk I/O and type inference overhead
Better than Map(String, String) - Map type loads entire structure into memory for any query
Memory implications - For our user properties pattern, if ordered by contact_id, all rows must be scanned for key-based filtering which is not performant
This is why we created the normalized contact_attributes table - it allows ordering by attribute_key and building indexes on attribute values.
For events, we are good with JSON for now, as we filter by event name and limit search size already
How Partitioning Works in ClickHouse
Partition Structure on Disk

Advanced Indexing and Optimization Strategy
1. Partition-Level Optimization
Weekly Partitioning Strategy:
Benefits:
7x Fewer Partitions: 52 vs 365 partitions per year
Faster Date Ranges: 40% improvement in date range queries
Better Merges: Larger partitions merge more efficiently
Reduced Metadata: Lower memory overhead for partition tracking
Partition Pruning Example:
2. Specialized Skip Index Strategy
MinMax Indexes for Range Queries:
Bloom Filter Indexes for Existence/Equality:
3. Granule Structure and PREWHERE
We use PREWHERE for event_names and event timestamp filters filters

JSON Logic Query Engine Architecture
Complete Query Pipeline
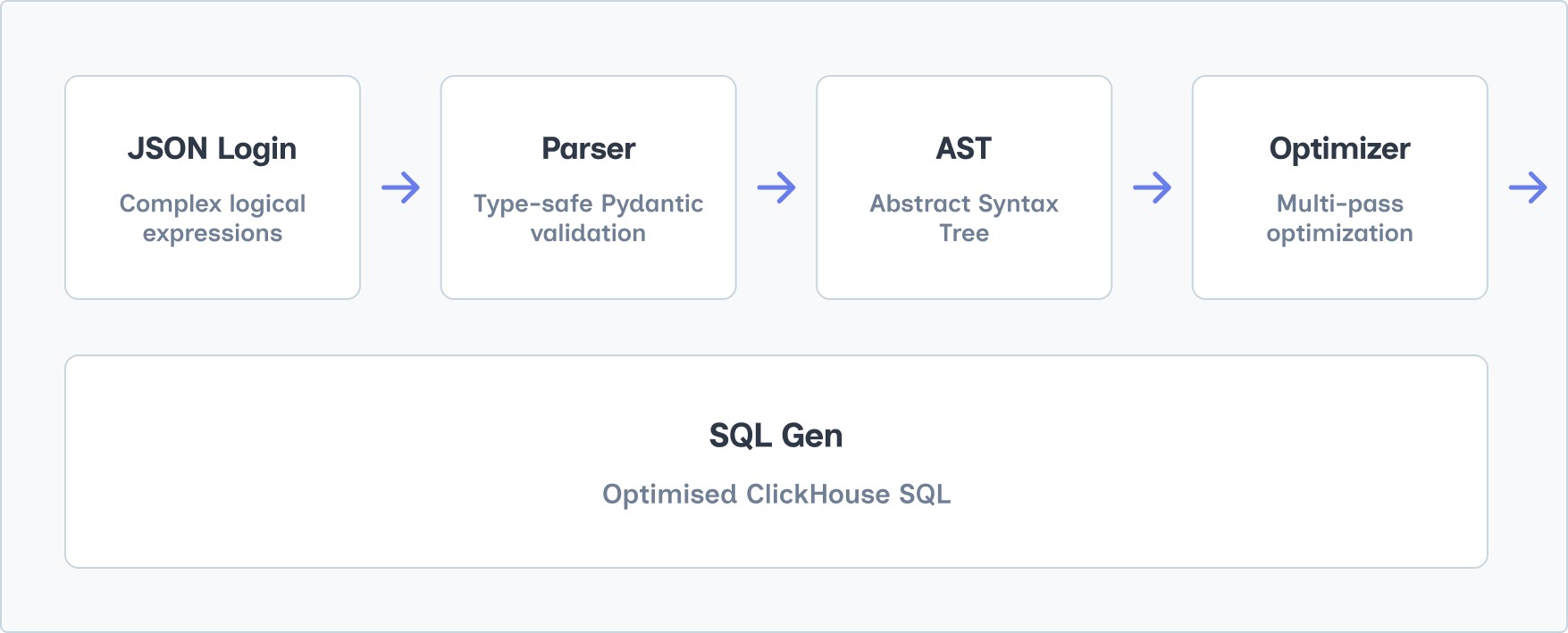
The Translation Challenge
Our query engine solves a complex problem: how do you translate human-readable logical expressions into highly optimized ClickHouse SQL that can leverage our multi-table architecture?
The challenge isn’t just syntax translation - it’s about making intelligent decisions about:
Which table to query (events vs attributes vs properties)
Which indexes to leverage (bloom filters vs minmax vs set indexes)
How to optimize query execution (PREWHERE vs WHERE vs HAVING)
When to use JOINs vs subqueries vs UNION/INTERSECT
Query Pipeline Architecture
Our translation pipeline follows a four-stage optimization approach:
Stage 1: JSON Logic Parsing
We chose JSON Logic because it provides a standardized way to express complex logical operations that marketing teams understand. A typical audience query might be: “Find users who purchased something expensive recently AND (live in the US OR are premium customers OR haven’t provided a phone number).”
Stage 2: AST Construction
The parser converts JSON Logic into a type-safe Abstract Syntax Tree. This gives us compile-time guarantees and enables sophisticated analysis. Each node in the tree knows its context (trait vs behavior) and can make intelligent routing decisions.
Stage 3: Context Analysis
Before generating SQL, we analyze the entire query structure to understand:
What data sources we need (events, attributes, properties)
Which conditions can benefit from PREWHERE optimization
Whether we need aggregations (COUNT, HAVING clauses)
How to best combine multiple conditions (INTERSECT vs UNION)
Stage 4: SQL Generation with Optimization
Finally, we generate ClickHouse SQL that’s specifically optimized for our table structure and leverages all available indexes and partitioning strategies.
Hybrid Storage Strategy
We developed a three-tier storage strategy that balances performance and flexibility:

Automatic Tier Selection
Our query engine automatically routes variables to the appropriate tier based on predefined mappings and runtime analysis. Users write simple logical expressions - the engine handles the complexity.
Context-Aware Optimization Engine
Different types of queries require completely different optimization strategies:
Trait Queries (User Attributes)
Strategy: Direct table access or normalized attribute filtering
Optimization: Use direct columns when available, leverage attribute_key indexes
Behavior Queries (User Actions)
Strategy: PREWHERE optimization for event filtering, JSON property access
Optimization: Place high-selectivity conditions in PREWHERE, use partition pruning
Mixed Queries (Traits + Behaviors)
Strategy: Generate separate subqueries and combine with INTERSECT/UNION
Optimization: Parallel execution of independent conditions, intelligent combination
Query Optimization Strategies
1. PREWHERE Optimization Engine
The PREWHERE Challenge
ClickHouse’s PREWHERE clause is one of its most powerful features, but knowing when and how to use it requires deep understanding of data distribution and query patterns. Our engine automatically identifies conditions that benefit from PREWHERE placement.
Automatic Condition Classification
Our system analyzes each predicate and classifies it into one of three execution phases:
PREWHERE: High-selectivity conditions that can eliminate most rows early
Event name equality (e.g.,
event = 'purchase') - typically filters 90%+ of rowsDate ranges that enable partition pruning - reduces data scanned by 10-100x
Direct column comparisons on indexed fields
WHERE: Standard filtering conditions that run after PREWHERE
JSON property comparisons that require type casting
Complex logical combinations that can’t be optimized
Lower-selectivity conditions that don’t warrant PREWHERE cost
HAVING: Aggregate-dependent conditions that must run after grouping
Event count requirements (e.g.,
event_count >= 3)Time-window based aggregations
Cross-event pattern matching
2. Multi-Table Query Strategy
The Multi-Table Challenge
When a query involves both user traits and behaviors, we face a fundamental decision: Should we JOIN tables or use set operations like INTERSECT/UNION? The wrong choice can make queries 10x slower.
Intelligent Strategy Selection
Our engine analyzes the complete query structure before choosing an execution strategy:
Strategy 1: Direct Count Optimization (Fastest - ~200ms)
For queries involving only direct columns (like computed lifecycle metrics), we skip subqueries entirely and apply uniqHLL12() directly to the source table. This eliminates unnecessary data movement.
Strategy 2: Single-Table Optimization (Fast - ~400ms)
Pure trait queries or pure behavior queries can be optimized within a single table using specialized indexes and column-store optimizations.
Strategy 3: INTERSECT/UNION Strategy (Moderate - ~800ms)
Mixed queries generate independent subqueries for each condition type, then combine results using set operations. This allows parallel execution and optimal index usage per table.
Strategy 4: Complex JOIN Strategy (Slower - ~1500ms)
Only used when set operations aren’t feasible, typically for queries requiring cross-table correlations or complex aggregations.
Why Set Operations Beat JOINs
In most analytical queries, INTERSECT and UNION outperform JOINs because:
Each subquery can use its optimal indexes independently
ClickHouse parallelizes set operations efficiently
Memory usage is more predictable with large result sets
Query planning is simpler and more reliable
Example

Performance Analysis and Benchmarks
Query Performance by Type
Query Type | Avg Response Time | P95 Response Time | Optimization Used |
|---|---|---|---|
Simple Trait | 450ms | 800ms | Direct Count |
Multiple Traits (AND) | 520ms | 900ms | Normalized Attributes |
Multiple Traits (OR) | 680ms | 1200ms | UNION Strategy |
Simple Behavior | 480ms | 850ms | PREWHERE |
Behavior + Count | 520ms | 950ms | PREWHERE + HAVING |
Behavior + Properties | 1800ms | 2500ms | PREWHERE + WHERE |
Mixed (Simple) | 750ms | 1300ms | INTERSECT |
Mixed (Complex) | 1400ms | 2200ms | Multi-table INTERSECT |
Future Enhancements and Roadmap
Event Property Index Optimization
Currently our slowest queries involve event property filters. Analysis shows performance degrades for low-selectivity keys (present in most rows). We’ll implement:
Periodic job to identify frequently-used keys
Build secondary indexes based on subcolumn types
Automatic index recommendation system
Precomputed Event Counts
Create materialized views for event counts per date, eliminating aggregation overhead for queries without property filters.




