
Rajat Goyal is an engineering leader at Aampe, where he helps build the adaptive decisioning systems behind Aampe’s AI agents. His work focuses on how software can learn from user behavior in real time and make increasingly personalized decisions across channels, messages, timing, and product experiences.
Thompson Sampling: Why the Simplest Adaptive Algorithm Outlearns Rules, Campaigns, and A/B Tests
When I joined Aampe, Thompson Sampling was one of the first concepts I needed to internalize. Not in a "read the Wikipedia page" way. In a "this is one of the powers we equip our agents with" way.
So I did what I always do when I need to actually understand something: I built something random with it.
The result is a bomber game where you play against an AI opponent that uses Thompson Sampling to learn how to hit you. You move, it adapts. Craters reshape the terrain, it recalculates. You reposition, it explores until it finds you again.
What started as a TIL exercise during onboarding turned into something genuinely useful for building intuition about how powerful adaptive systems can be, and why no rule-based system or team of humans making campaign decisions can compete with even a basic implementation.
Play first, read second
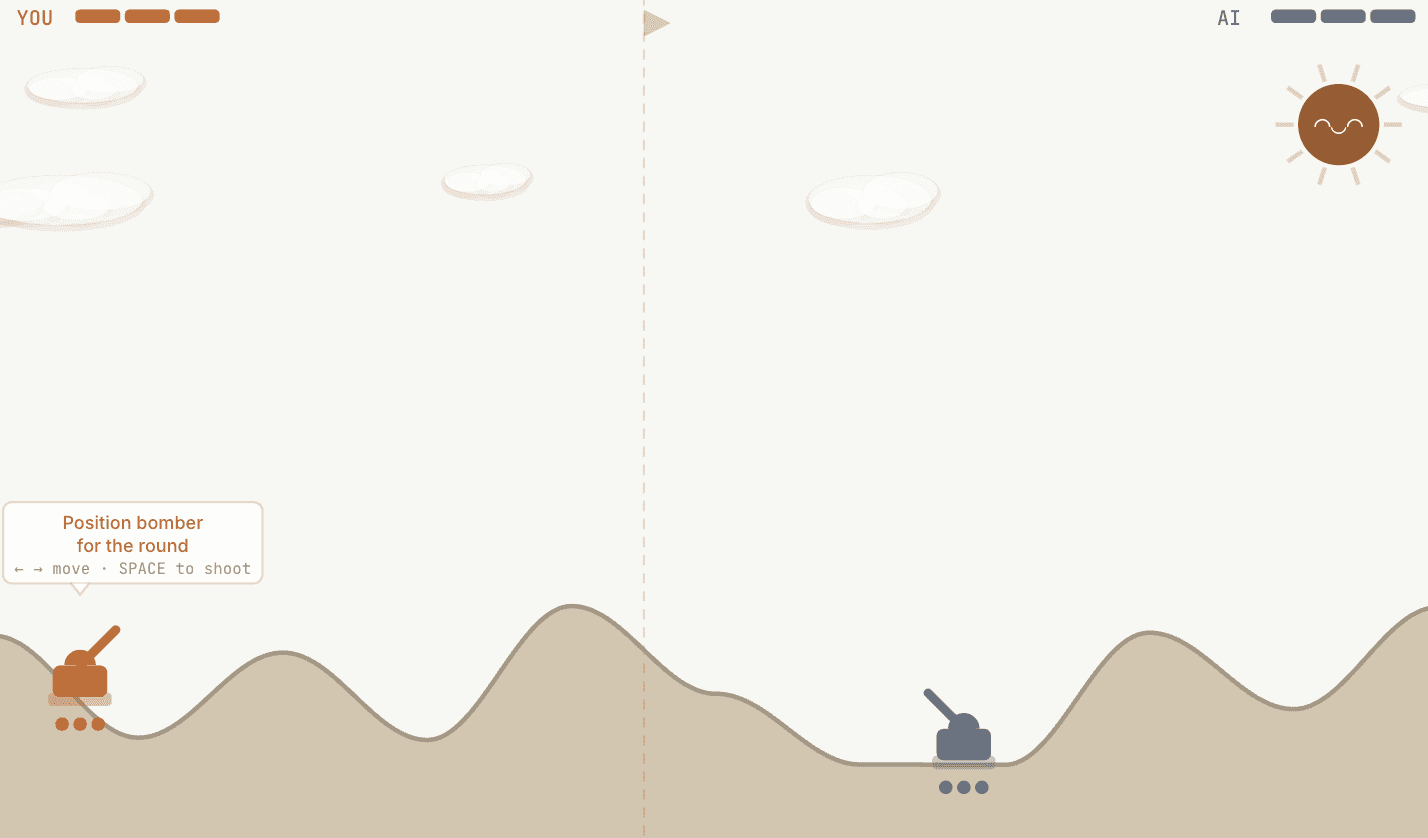
Before I explain anything, go play a few rounds: thompsonbomber.vercel.app
The controls are simple. Arrow keys to move your tank, spacebar to fire. The AI fires back using Thompson Sampling to decide how much power to put behind each shot. Watch the belief chart on the right. Each bar shows the AI's current best guess of how often that power level wins (the posterior mean). Tall = "I think this works." Short = "I don't think this works." The opacity of the bar shows confidence: faded means the AI hasn't tried it much, solid means it has lots of evidence. The yellow bar is the option the AI just picked.
Play 10-15 rounds. Then move to a different position and watch what happens.
Done? Good. Now let me explain what you just saw.
What the AI is actually doing
Every time the AI fires, it faces a choice: stick with the power level that's worked before, or try something different that might work better.
This is the explore-exploit tradeoff, and it shows up in every system that makes repeated decisions under uncertainty. Which ad to show. Which push notification to send. Which product recommendation to surface. Which treatment to assign.
Thompson Sampling solves this with a beautifully simple idea. Instead of tracking a single "best guess" for each option, track your entire uncertainty about it using a probability distribution. In our game we use a Beta distribution parameterized by successes and failures. Beta is not the only choice though. It just happens to be the natural fit when outcomes are binary (hit/miss, click/no-click), and it's what we use here. For richer models (neural networks predicting probabilities, mixture models, etc.) you'd swap in a different posterior representation while keeping the same sample-and-pick algorithm.
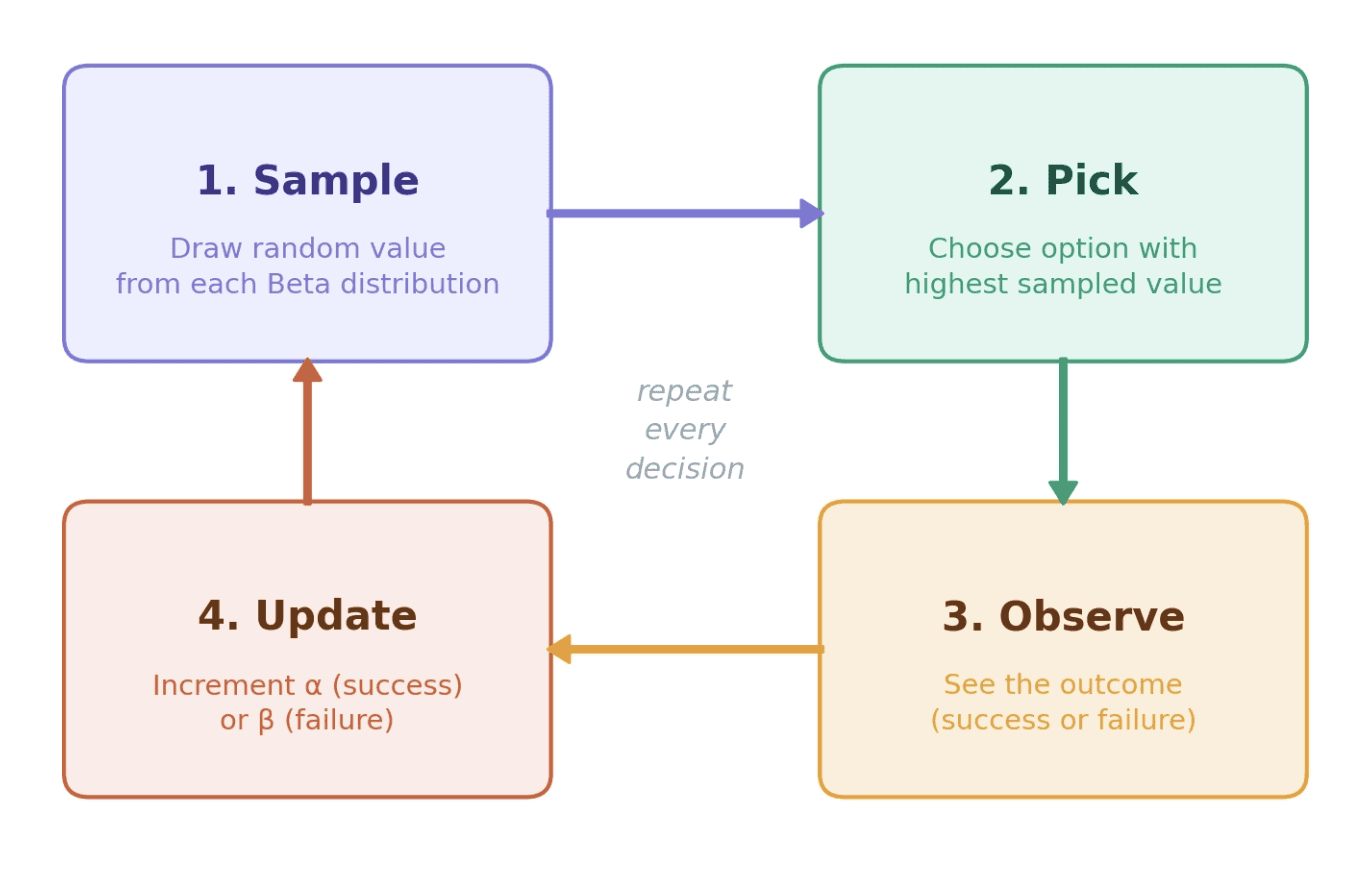
In a very simplistic view, the algorithm is four steps:
For each option, sample a random value from its Beta distribution
Pick whichever option produced the highest sample
Observe the outcome (hit or miss, click or ignore)
Update the chosen option's distribution
That's it. No tuning parameters. No exploration schedule. No rules about when to stop experimenting.
The magic is in the sampling. An option you're uncertain about has a wide distribution. Sometimes its random sample will be high, sometimes low. So it gets explored occasionally. An option you're confident about and that performs well has a narrow, high distribution. Its samples are consistently high. So it gets exploited reliably. An option you know is bad? Narrow and low. It gets ignored.
The algorithm automatically allocates exactly the right amount of exploration, proportional to your uncertainty. Mathematicians call this probability matching: the probability of choosing an option is proportional to the probability that it's actually the best one.
The intuition is Bayesian at its core. You start with a prior belief (uniform: "I don't know anything"), observe evidence, and update your belief. The Beta distribution is a natural fit here because it's conjugate to the Bernoulli likelihood. That means every success/failure observation gives you a clean, closed-form posterior update. No expensive retraining. No batch jobs. Just increment alpha or beta and sample again. With a Beta-Bernoulli setup like this, the per-decision cost is essentially zero. Scaling Thompson Sampling to richer models (e.g. neural networks producing posterior distributions over P(click | context, ad)) is an active research area. The algorithm itself stays cheap; computing the full posterior is what gets expensive.
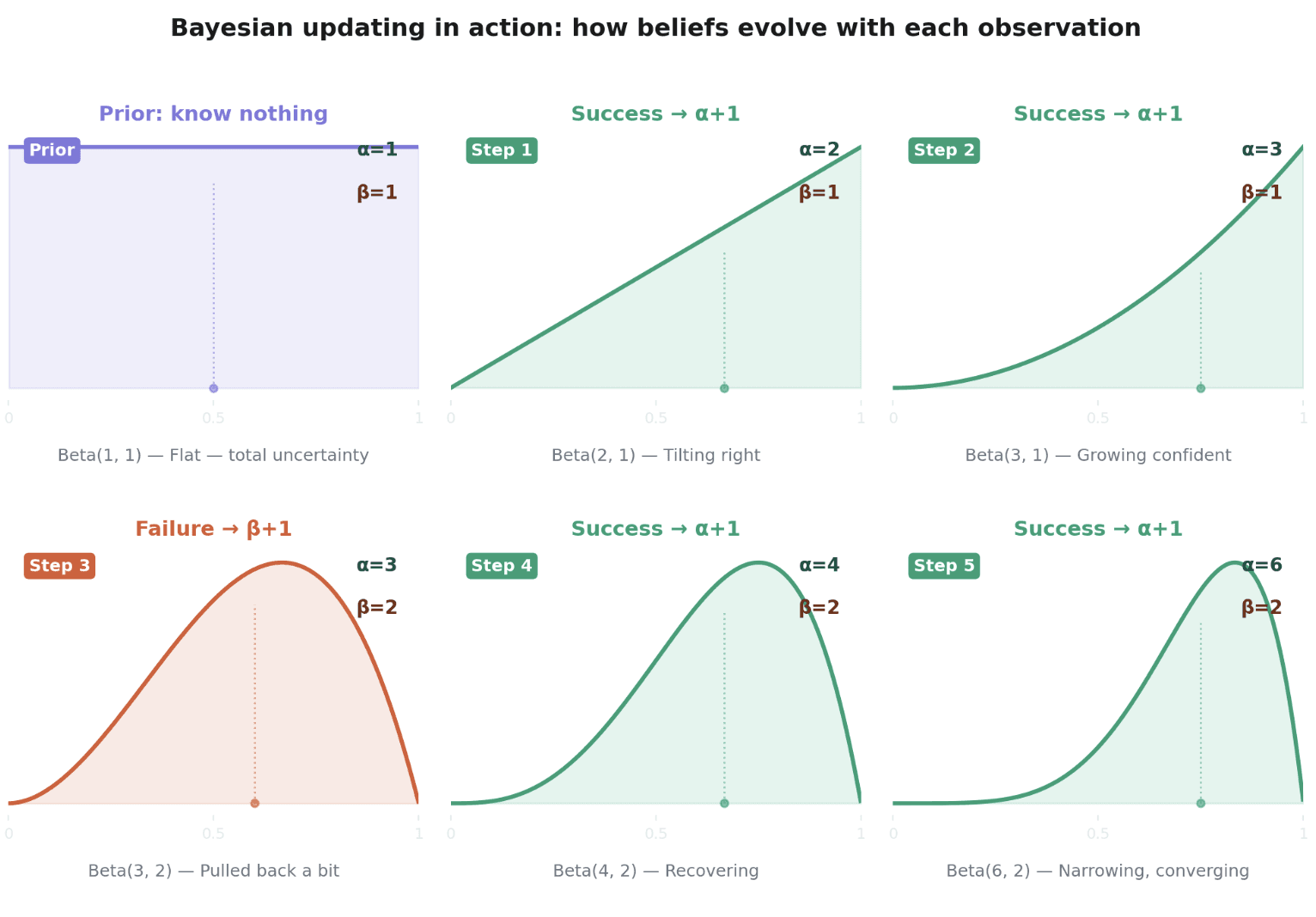
If you watched the belief chart in the game, you saw this play out visually. Early on, all the distributions are wide and overlapping. The AI is trying everything. After several rounds, one region gets tall and narrow. The AI has converged. Move your tank, and those confident distributions suddenly stop working. Exploration resumes.
When the situation changes, the AI's beliefs shift. Each new failure on the previously-best power level adds to its β count, gradually lowering its posterior mean and pushing the AI to explore again. In production systems, you usually accelerate this by adding a sliding window (only count recent observations) or decay (down-weight old evidence). Aampe uses this kind of decay so agents stay responsive to changing user context instead of being anchored to ancient behaviour.
Think about what this means in real life. A user who just moved cities, changed jobs, or had a baby has fundamentally different needs today than yesterday. A rules-based system keeps sending them the same content because they're still in "segment X." A campaign calendar doesn't know or care. A PM reviewing weekly dashboards might notice the shift in aggregate metrics weeks later. An adaptive system notices on the very next interaction and starts exploring again.
For a deeper technical walkthrough of how contextual bandits actually behave in production, including population priors, individual parameters, and semantic action spaces, Aampe's engineering team has written extensively about the machinery under the hood.
Why this matters more than you think
Here's the thing that surprised me most during onboarding: most CRM and lifecycle marketing teams still haven't internalized the gap in their current setup. They use rules. They use segments. They use A/B tests. And they don't realize how far behind their systems have fallen and just how much real value they are leaving on the table by not adopting agentic personalization with adaptive learning capabilities.
Rules go stale faster than teams can update them
A rules-based system says "if user is in segment X, send message Y." Someone wrote that rule based on what they believed was true at some point. Maybe it was true then. Is it true now? Nobody checks often enough. Context changes. User behavior shifts. The rule keeps firing.
The bomber game makes this tangible. Imagine if instead of Thompson Sampling, the AI just used a fixed rule: "always fire at 65% power." It would work exactly as long as you stand still. The moment you move, it keeps shooting at the empty spot. Adaptive systems learn from interaction. Rules don't.
A/B testing picks one winner for everyone
A PM running experiments might manage 52 tests a year if they're disciplined. Each test picks a "winner" variant for the entire population. Even then, it requires real skill to evaluate results within a week's timeframe and draw the right conclusions from all these experiments. But the deeper problem is this: statistical significance for a group does not mean individual-level effectiveness.
Variant A might win overall, but Variant B might work better for 30% of your users. An A/B test can't tell you that. It picks one winner and moves on. Thompson Sampling continuously learns what works for whom, adjusting per user rather than declaring a single champion.
A traditional A/B test also locks a fixed percentage of your traffic into a control group for the duration. That's a tax on your users' experience. Thompson Sampling naturally reduces exploration as confidence grows, so you're never burning more exploration than the current uncertainty warrants.
To be clear, A/B tests are still a valuable tool. They're great for measuring the impact of large, discrete changes: a new checkout flow, a redesigned onboarding, a pricing change. What they're not great at is continuous, per-user optimization across hundreds of small decisions. That's where adaptive methods take over. At Aampe's we argue, experiments shouldn't stop at measurement; they should be continuous learning infrastructure.
Context changes everything
The best action depends on who you're talking to, when, and what just happened. Thompson Sampling handles this through contextual bandits: maintain separate beliefs per context.
In the bomber game, context shifts constantly. You reposition between rounds. The bot moves too. Craters from previous hits reshape the terrain, changing elevation and line of sight. The distance between the two tanks is different every round. The AI doesn't get told any of this explicitly. It just sees that what worked last round stopped working, and it starts exploring again. Each of these shifting conditions is a contextual parameter the AI adapts to on its own.
This is a miniature version of what production systems face. At Aampe, each user has their own agent running different AI decisioning algorithms (Thompson Sampling being one of them) across combinations of message content, timing, and channel. The agent learns what works for each person through interaction rather than relying on pre-built segments. The explore-exploit balance adjusts per person, not per population.
What production scale actually looks like
The bomber game has one context dimension (wind) and one action dimension (power level). That's 3 wind conditions times 20 power buckets, so 60 cells to learn.
Production is a different universe. Consider the levers a real system has to decide across. For example: which channel (push, email, SMS, in-app), what time of day, which day of the week, how frequently, which screen or placement, how long or short the message should be, what topic or value proposition, what tone, what visual style, what greeting, what CTA. And then the copy itself. Each of these is a dimension with multiple options. Even a small subset of these creates millions of component combinations per user. And this is not an exhaustive list. Half the context signals that matter are things you cannot even feature-engineer upfront.
You can't A/B test this massive combinatorial space. You can't write rules for them. You need a system that explores efficiently and converges on what works per person.
The action space is just the beginning. The reward signal itself is complex. "Did they open?" is easy to measure but not always what you want to optimize. "Did they convert?" is harder to attribute. "Did they stay engaged over the next 30 days?" requires patience. Production systems need to balance multiple business goals simultaneously, not just maximize a single metric.
Thompson Sampling is not a silver bullet. It's one toolset in a family of AI decisioning algorithms that Aampe uses for adaptive decision-making, alongside contextual weighting, decay functions, and causal inference methods. But the core insight holds: when the decision space is combinatorial and context shifts constantly, no team of humans writing rules or reviewing dashboards can keep up.
This is what Aampe builds for. The combinatorial scale of these decisions is something no human team can manage manually. Each user gets their own agent that learns across their entire journey. Whether the interaction happens through Messages (push, email, SMS) or Surfaces (in-app personalization), the explore/exploit learning is shared. Every signal from every channel feeds back into the agent, building a deeply personalized super agent for that one user. It's the equivalent of having a dedicated human working around the clock to observe, understand, and personalize the experience for a single individual. Except it scales to millions.
If any of this resonates with the scale of decisions your team faces, reach out to Aampe. We'd love to talk about it.
Go play the game
If you made it this far without playing, now's the time: thompsonbomber.vercel.app
Watch the AI's beliefs converge. Move and watch them reset. Toggle "Play Fair" mode and experience what it's like to make decisions with sparse feedback. No full picture, just distance hints after each shot.
That feeling of uncertainty, of needing to explore before you can exploit, of watching your beliefs narrow and then get blown open when conditions change? That's what every system that interacts with humans faces, every day, at scale.
Thompson Sampling doesn't eliminate the uncertainty. It just handles it with mathematical elegance instead of gut instinct and stale rules.
If your team is still relying on static rules, fixed journeys, or one-off tests to decide what each customer should see next, Aampe can help. Our agents continuously learn from every interaction to personalize messages, timing, channels, and in-app experiences for each individual user. Meet with Aampe to see how adaptive personalization can work across your customer journey.