
The problem
Most product teams have a version of this problem. You care about the product feeling polished: the button that's a few pixels off, the empty state that doesn't explain itself, the bit of copy that reads awkwardly. But none of that work ever quite makes it to the top of the list. It's always sitting behind the next big feature, and the next big feature is always more urgent. So the small stuff accumulates. Everyone agrees it matters, yet somehow no one ever gets to it.
That was where we were with Aampe Composer. We had a steadily growing pile of small bugs and rough edges that we genuinely wanted to fix, but which consistently only received minimal bandwidth for prioritization. Patches started as an attempt to deal with that pile: an agent that could pick up those tickets and carry them all the way through to a fix, with as little disruption to the engineering team as possible.
None of these tickets were hard. We had a panel that only took up about two-thirds of the window when we wanted it to use the full width. We had a form field that showed a datetime without making the timezone explicit, which was an easy way to confuse someone. Each one was only a few minutes of work in isolation. What made them expensive was the overhead that comes with picking up any ticket at all. That overhead meant we eventually started clumping them together into omnibus tickets, hoping their collective importance would help them get prioritized. But those bigger tickets only got picked up roughly once a quarter, so we weren't doing great on turnaround time.
Patches’ fundamental contribution was solving the overhead problem by changing who could move a ticket forward.
Minimizing engineering overhead
The thing that makes Patches useful isn't really that an agent can write the code. It's that it changes who can move a ticket forward, and when an engineer needs to be involved at all.
With Patches, a designer or someone on customer success can flag an issue directly, watch it make progress, and do the QA themselves in a live environment. An engineer only comes in at the very end, to review code for a fix that's already been QA'd and confirmed to work.
That ordering matters more than it might sound. Normally even a tiny ticket costs an engineer a real chunk of time: pulling the branch, rebuilding the context in their head, going back and forth with whoever reported it to understand what they actually meant, writing the fix, committing, and waiting for CI. It's easy for a one-line change to eat an hour or more. With Patches, the engineer skips all of that and just reviews a diff they already know works. That turns an hour-plus into a few minutes, and across a whole backlog of small things, it adds up to a surprising amount of polish for very little engineering time.
How it works
The whole thing runs through Linear and GitLab, so most of it happens in tools the team already lives in. A single ticket moves through roughly these steps:
A designer or someone on customer success files a Linear ticket and labels it so Patches knows to pick it up.
Patches reads the ticket and posts a comment with any clarifying questions.
The ticket creator answers. Once Patches has enough context, it designs a solution, plans the implementation, and creates a set of tasks in the repo. If the work is complex enough, it also breaks things into sub-issues in Linear.
Patches does the implementation work and opens a draft merge request in GitLab.
The merge request spins up a feature deployment of the frontend. Patches links to it in a Linear comment and asks the ticket creator to do QA.
The ticket creator clicks around the live deployment and leaves feedback on anything that needs fixing.
Patches fixes what came up and asks for QA again. This loops until the fix looks right and the ticket creator signs off in a comment ("Looks good!").
Patches moves the merge request out of draft and assigns a developer to review it.
The developer reviews the code and flags any issues. Patches responds and fixes them, and the developer eventually approves the MR.
Once the MR is approved, Patches merges it and the deployment pipeline ships it.
The nice part is where the humans sit in that loop. The ticket creator is involved early and during QA, exactly when their judgment matters, and the engineer only shows up at step 9, to review code for something that already works.
Our lead designer, Madhuri, even built a Chrome extension to make the process of filing tickets (complete with screenshots and other context) easier for the whole team.
What makes it work
A few pieces had to come together for this to feel like working with a teammate rather than fighting a tool.
The first is a solid Linear integration. Patches doesn't just grab a ticket and start guessing. It can ask clarifying questions and gather context before it commits to a plan and breaks the work into tasks, and the people on the other side can answer in plain text or drop in a screenshot, the same way they would with a colleague.
The second is a good frontend dev harness. The repo has a CLAUDE.md that explains how things work, and Patches can run a local copy of the app wired up to our staging backend. It can also take screenshots and post them back into Linear, which it uses to show a fix, ask "is this what you meant?", or give visual feedback. That loop is a big part of why the conversation feels real.
The third is that our deployments are easy and the QA happens in a live environment, so people can actually click around on the change and give specific feedback instead of trying to imagine it from a diff.
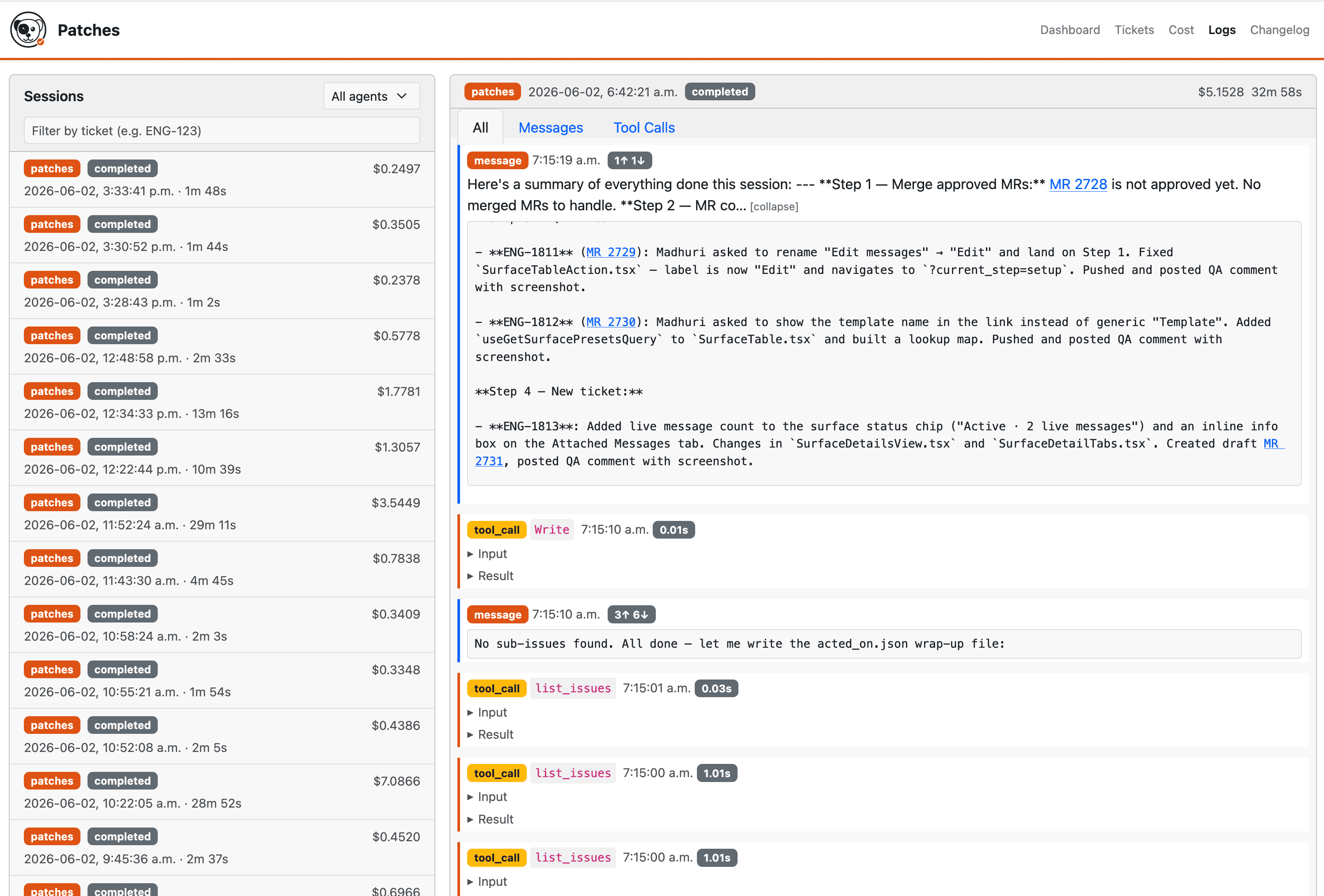
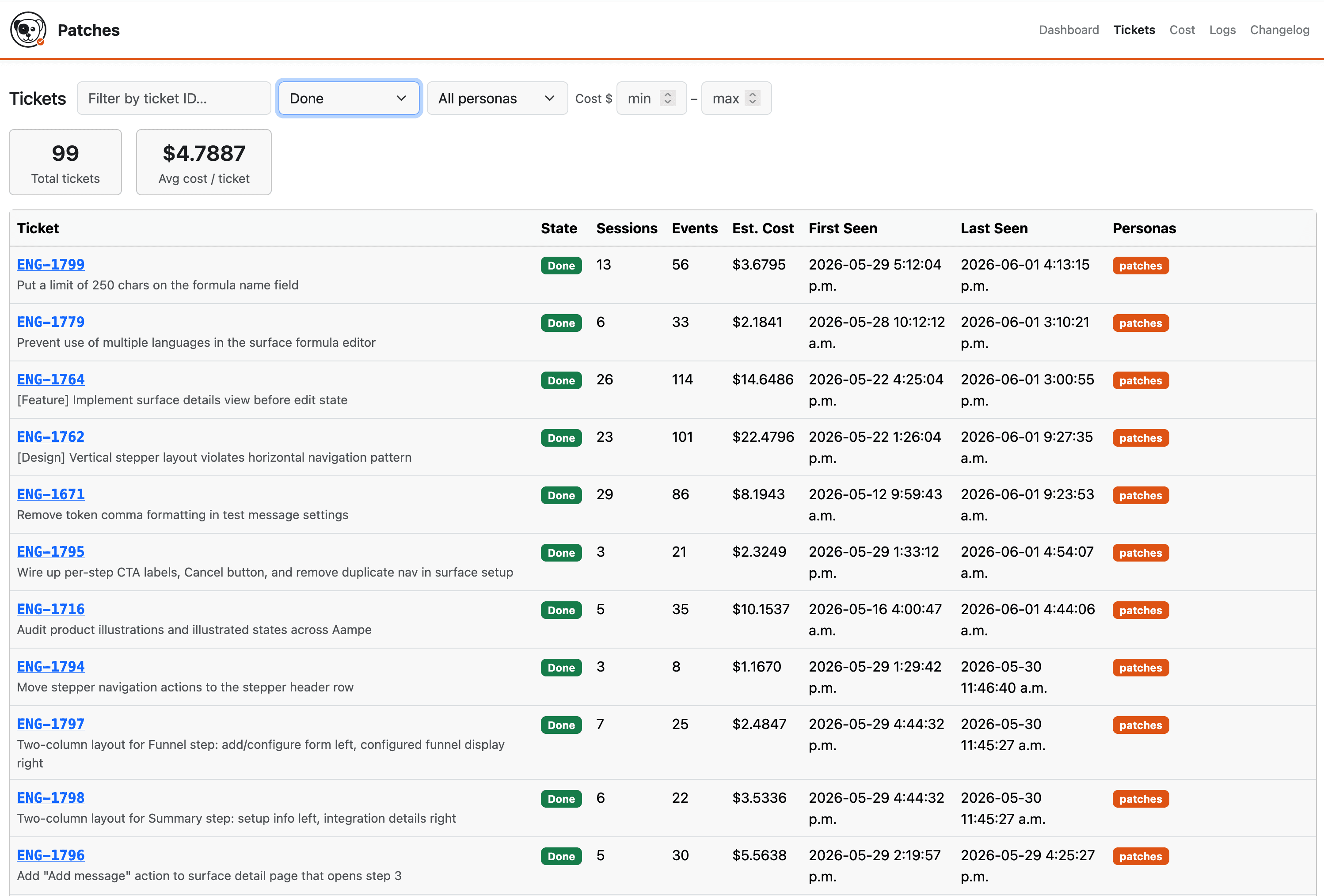
And the last piece is a small dashboard I built to keep an eye on what Patches is doing: sessions, cost, which tickets it's worked on, and so on.
Why it's frontend-only, at least for now
There were two reasons to keep Patches on the frontend.
One is that the frontend is what customers actually see, so it's where polish, or the lack of it, shows up most. If you're going to spend effort cleaning things up, that's the place where it's most visible.
The other is that the risk is easy to contain. A bad frontend change breaks a view; it doesn't drop a database. Keeping Patches on the frontend meant I was comfortable letting it run on its own without worrying about what it might do to production data. I don't want my next post to be a cautionary tale.
How it's gone so far
Over the last month Patches has closed 99 Linear issues at a cost of around $625, and that figure also covers work still in progress on another 43. Some of those tickets were one-line copy changes; a few grew into entirely new views in the frontend, and the cost of each varied with complexity and how many iterations the agent had to go through.
For example, a simple styling change on a badge cost less than $1. A brand new view for our Surfaces feature, complete with multiple tabs, cost a total of about $17 over 25 sessions.
The economics have really changed how we approach feedback on the frontend. When an issue was flagged, our previous approach was to file a cleanup ticket for an engineer to pick up when they had time. Now we just let Patches have a crack at it, and most of the time it makes short work of the issue. Even when it took a few rounds of back and forth, with a designer leaving Linear replies like "Why won't you just FOLLOW THE DESIGN I SHARED!?", the economics still made sense. For the engineering team, anyway. The designers might tell you a different story.
What I learned
A few things genuinely surprised me along the way.
The biggest one was that a single agent beat several specialized ones. I started out with three separate agents, each with its own identity: one to triage issues and design a solution, one to implement it, and one to review the work and keep tickets moving. It looked sensible on paper. In practice the coordination cost was brutal. The agents spent a lot of time and tokens creating sub-tickets just to hand work off to each other, and they kept losing important context in the gaps between them. When I collapsed all of that into one agent that owned the whole job, things got much smoother. Nobody was waiting on anyone else for a spec or an answer; one agent gathered the context it needed, made a plan, and carried it out.
Another lesson was that determinism is cheap, and I'd been overcomplicating things. My first version let the agent decide for itself whether there was new work by searching Linear. In hindsight that was a slightly delusional way to use an AI, because it's trivial to write a script that checks whether new tickets exist or known tickets and MRs have changed. Once I wrapped the agent in that kind of deterministic harness, I could go from waking it up once an hour to fish for work to running a check every minute and only spinning it up when there was actually something to do. That was both cheaper and more responsive.
The last surprise was maybe the most fun. I'd assumed the agent would simply do whatever anyone asked. Instead I caught it pushing back now and then, suggesting a different approach when a request was about to blow up the scope of a ticket. I didn't expect that, but I was happy to see it.
A closing thought
What I keep coming back to is how low-risk this turned out to be. Patches didn't ask anyone to hand off control or add a lot of friction to their process. It gave the design and customer-facing teams a way to unblock themselves on work that used to sit waiting on engineering, while engineering kept the final say on whether the code was actually good. Nobody lost the part of the process they cared about.
I think of Patches as an augmentation of the team rather than a replacement for anyone on it. It didn't take work away from engineers; it took away the parts of small tickets that were pure overhead and left them with the part that needs their judgment. And it gave the people closest to the rough edges, the designers and CS folks who noticed them in the first place, a way to actually do something about them. The team got more done without anyone giving up the thing they're good at.
It also brought about a fundamental shift in how the team thought about frontend bugs. People had always flagged issues and filed tickets for them, but there was a quiet assumption that actually getting any of it fixed was going to take a long time. About halfway through the month, I noticed that that reflex had changed. The first reply on any Slack thread raising something like "hey, this doesn't look quite right" had become a question: "Can Patches take this?"