
Infrastructure Friction as a Signal:
Why We Moved 600+ Airflow Workflows from Cloud Composer to Astronomer
Divyang Prateek Pandey is a founding engineer at Aampe, where he architects the systems behind the company's adaptive AI agents and leads key strategic infrastructure initiatives. He owns the data pipelines, orchestration layer, and core architectural decisions that allow Aampe's agents to learn from customer behavior and improve over time.
Harshit Soni is an engineer at Aampe, where he works across platform infrastructure, CI/CD systems, and cloud orchestration. He builds and maintains the GCP infrastructure, Terraform-driven IaC, and deployment pipelines that keep Aampe's services running across multiple regions.
At Aampe, our product helps teams move from static campaign management to adaptive customer engagement. That product promise depends on infrastructure that can handle constant learning, decisioning, orchestration, and feedback across large customer populations.
The same principle applies inside our engineering systems.
When infrastructure is working well, it disappears into the background. It gives engineers short feedback loops, predictable operations, clear failure modes, and enough flexibility to match the work actually being done. When it stops doing that, the cost does not always appear as one major outage. It appears as avoided upgrades, manual retries, idle capacity, slow onboarding, and workarounds that gradually become normal.
That is what happened with our Airflow infrastructure.
We run data pipelines for customers across multiple industries. Apache Airflow sits at the core of our platform, orchestrating hundreds of DAGs that support data exports, message scheduling, analytics, and downstream customer workflows. For a long time, Google Cloud Composer was our managed Airflow service.
It worked, until the operating model around it stopped fitting the system we were building.
This is the story of why we moved more than 600 workflows from Cloud Composer to Astronomer, what we had to change, and how the move reduced operational friction across our engineering team.
The friction we almost normalized
Most infrastructure decisions feel permanent once they are made. You choose a vendor, build around it, and the switching cost starts to feel too high to revisit.
That can make teams too tolerant of friction.
On Composer, that friction showed up in ways that were easy to explain away. Environment updates took hours and sometimes failed without useful logs. Mixed workloads did not scale cleanly. Worker evictions caused task failures that required human intervention. New developer onboarding took half a day just to get a local environment working.
None of those issues looked large enough on its own to justify a migration of 600+ workflows.
Together, they changed how the team operated.
We avoided Airflow upgrades because they were painful. We kept more workers running than we needed because autoscaling was unreliable for our workload mix. We accepted manual retries as part of on-call operations. We treated slow local setup as the cost of doing business.
That was the signal. Composer was no longer just hosting Airflow for us. It was shaping our engineering behavior.
For a company building adaptive systems, that mattered. Aampe’s product is built around the idea that learning should compound rather than reset. Our infrastructure needed to support that same operating philosophy.
Why we left Cloud Composer
Environment updates were opaque
Updating a Composer environment took hours. When an update failed, we often received a timeout and little else. No useful error message. No clear log output. No obvious path to resolution.
Debugging became guesswork.
Over time, we updated less often than we should have. That left us behind on Airflow versions and created technical debt that became harder to pay down with every delay.
Autoscaling did not fit our workload mix
Our Airflow workloads are not uniform. Some sensors finish in a few seconds. Some export tasks run for tens of minutes. Some tasks need very little memory. Others need much more.
Composer’s autoscaling behavior struggled with that mix. When short tasks finished, workers could scale down while longer-running tasks were still mid-execution. Those tasks would fail, retry, and eventually complete, but the noise became part of daily operations.
We also could not route different task profiles to different worker pools in the way we needed. Everything competed for the same resources.
We were paying for idle capacity
Because autoscaling did not match our workload shape, we compensated by keeping a large standing pool of workers running.
Those workers were sized for the worst case. High memory. Enough count to absorb peak load. Always available because we did not trust scale-down behavior under mixed workloads.
That meant we were paying for idle capacity as insurance against operational instability.
Worker evictions created manual work
High-memory tasks running alongside lighter work would sometimes push a worker past its memory limit. In Composer, that meant the task failed without automatic recovery in the way we needed.
A person had to step in, inspect the failure, and retry the DAG.
The issue was not data quality. It was not business logic. It was infrastructure friction creating human work.
Local development took too long
Onboarding a new developer meant spending several hours getting a local environment working.
On Google Cloud Composer, we had to build a Docker instance that closely resembled the deployed environment. Engineers installed packages, waited for builds, hit failures partway through, debugged environment mismatches, and sometimes started over more than once.
A slow local feedback loop is expensive because every future change inherits it.
How we evaluated the cost of staying
The migration was not free. Moving more than 600 workflows meant touching production-critical systems, refactoring DAGs, validating customer workloads, and creating rollback paths.
So we compared the cost of moving with the cost of staying.
We looked at four categories.
Operational time. How much time were engineers spending on manual retries, failed updates, on-call noise, and infrastructure issues unrelated to customer data?
Engineering delay. How much work were we postponing because upgrades were painful or local development was slow?
Infrastructure waste. How much capacity were we keeping online because we no longer trusted the autoscaler?
Migration cost. How much work would it take to refactor DAGs, validate workflows, build new infrastructure, and move customers safely?
That comparison changed the decision. Platform cost alone would have undercounted the real cost of Composer. The larger cost was the way Composer had changed our team’s behavior.
What had to change in the code
Moving 600+ DAGs was not a matter of flipping a switch. The migration forced us to separate our Airflow logic from assumptions that had grown around the managed environment.
Catching up on Airflow versions
Composer had pinned us to an older Airflow version. One example was DAG run timeouts. We had been setting them as integers. In the newer Airflow version on Astronomer, they needed to be timedelta objects.
Before:
dagrun_timeout=settings.ASSIGNMENT_DAG_TIMEOUT_SECONDS,
After:
dagrun_timeout=timedelta(seconds=settings.ASSIGNMENT_DAG_TIMEOUT_SECONDS),
The code change was small. The lesson was larger. Version drift had accumulated because updating the environment was too painful.
Replacing GCP-native dependencies with Airflow-native hooks
The largest category of work was reducing our coupling to Google-native clients inside DAGs.
For BigQuery, we moved from directly instantiating a client to using BigQueryHook.
Before:
client = bigquery.Client(project=self.project_id)
return client
After:
hook = BigQueryHook(gcp_conn_id=settings.AIRFLOW_GCP_CONNECTION_ID)
return bigquery.Client(project=self.project_id, credentials=hook.get_credentials())
For Pub/Sub, we moved from the raw Google library to PubSubHook.
Before:
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(
settings.PUBSUB_PROJECT_ID, subscription_name
)
with subscriber:
response = subscriber.pull(
request={"subscription": subscription_path, "max_messages": 1},
retry=retry.Retry(deadline=300),
)
After:
hook = PubSubHook(gcp_conn_id=settings.AIRFLOW_GCP_CONNECTION_ID)
received_messages = hook.pull(
project_id=settings.PUBSUB_PROJECT_ID,
subscription=subscription_name,
max_messages=1,
ack_messages=False,
)
The hooks abstract credential management and let Airflow handle the connection lifecycle. The result was not just compatibility with Astronomer. It made our DAGs more portable.
Adding queue assignments
We added explicit queue routing so tasks could run on workers sized for their actual runtime and resource profile.
Removing custom Slack alerting
We had built our own Slack alerting because Composer did not cover the behavior we needed. Astronomer provided native Slack alerts, so we removed custom code and reduced one more maintenance burden.
Updating DAG start dates
This was simple work, but easy to miss across hundreds of DAGs. Small migration details matter when the surface area is large.
The architecture we chose on Astronomer
The migration gave us a chance to redesign the operating model around our workloads instead of forcing every task through one shared pool.
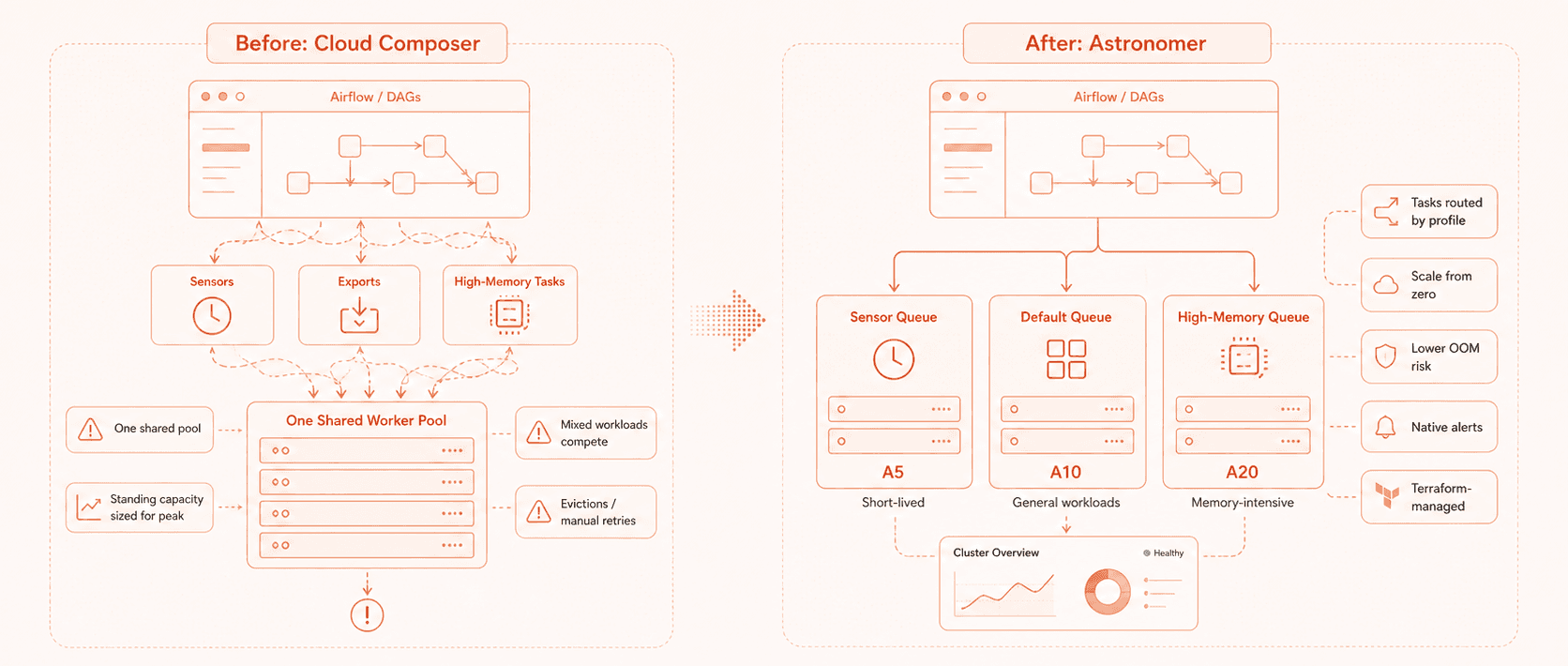
Worker queues based on runtime and resource profile
In Composer, everything ran on a single fixed worker pool. Because scale-down could interrupt longer-running tasks, we kept the pool large and over-provisioned.
On Astronomer, we split work into three queues.
A5 workers, with 1 vCPU and 2 GiB RAM, for sensors
A20 workers, with 4 vCPU and 8 GiB RAM, for high-memory tasks
A10 workers, with 2 vCPU and 4 GiB RAM, as the default queue
In the DAG, you declare which queue a task runs on:
sensor_task = SensorOperator(
task_id='my_sensor',
queue='sensor_queue', # Routes to A5 workers
...
)
heavy_task = PythonOperator(
task_id='my_export',
queue='high_mem_queue', # Routes to A20 workers
...
)
This addressed two of our biggest sources of friction.
Sensors now run on lightweight workers and do not trigger expensive worker spinups. High-memory tasks get the resources they need without putting unrelated work at risk. Default tasks run on a pool sized for normal execution rather than worst-case scenarios.
We stopped treating all Airflow work as if it had the same profile.
GCP authentication through impersonation
We did not want to give Astronomer’s workload identity direct permissions on our GCP projects. We also did not want to manage long-lived service account keys inside a third-party cluster.
We evaluated three options.
Create a GCP service account with the required permissions and add its key to the Astronomer cluster environment
Create a GCP service account with the required permissions and allow Astronomer’s workload identity to impersonate it
Grant permissions directly to Astronomer’s workload identity
We chose option 2.
The Astronomer cluster workload identity impersonates a tightly scoped service account inside our GCP project. That keeps permissions inside our project, avoids long-lived keys, and gives us control over the scope of access.
In the DAGs, that still looks simple:
hook = BigQueryHook(gcp_conn_id=settings.AIRFLOW_GCP_CONNECTION_ID)
Astronomer handles the impersonation chain behind the connection.
Infrastructure as code from the start
We defined the cluster configuration, worker queues, and networking setup in Terraform.
In Composer, we had tried to codify infrastructure but kept hitting gaps. The Terraform provider did not cover everything we needed, the documentation was sparse, and some setup remained manual. Reproducing an environment meant piecing together clickops, notes, and old internal conversations.
On Astronomer, we codified the setup from the start.
A simplified version of the queue setup looked like this:
resource "astronomer_cluster" "prod" {
provider_type = "gcp"
# cluster config
}
resource "astronomer_deployment" "prod" {
cluster_id = astronomer_cluster.prod.id
worker_queues = [
{
name = "sensor_queue"
worker_type = "a5"
min_count = 0
max_count = 10
},
{
name = "high_mem_queue"
worker_type = "a20"
min_count = 0
max_count = 5
},
{
name = "default"
worker_type = "a10"
min_count = 0
max_count = 20
}
]
}
Now the environment is reproducible. Need to audit the worker queues? Read the code. Need to create a staging environment? Apply the Terraform. Need to understand what changed? Review the diff.
That is the operating model we wanted.
A simpler GCP networking model
Astronomer requires VPC peering to reach the GCP resources that DAGs interact with. VPC peering does not work between networks with overlapping CIDR ranges.
Rather than maintain complex peering across multiple projects, we consolidated the relevant resources into a single GCP project with a single clean VPC. That made connectivity easier to reason about and removed a category of networking risk.
Separate clusters for development and production
Astronomer recommends a single cluster with separate deployments for staging and production, separated by IAM. We chose a different path.
We operate under SOC 2, and our architecture maintains network isolation between staging and production. IAM separation within a shared cluster did not meet our bar.
We run two independent Astronomer clusters, each with isolated network access to the appropriate environment. That means more infrastructure to manage, but it fits our compliance posture.
How we migrated without breaking production
We kept the rollout controlled.
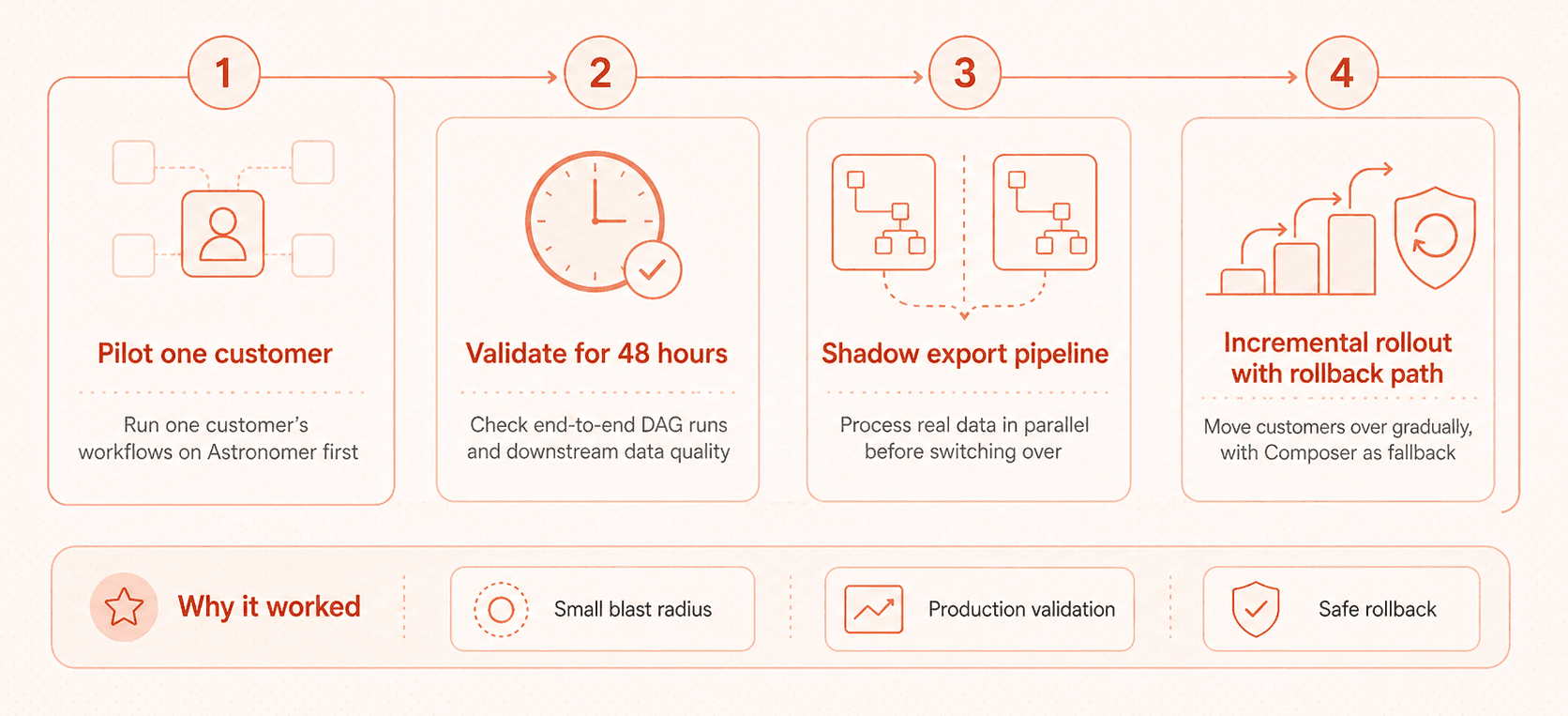
First, we ran the workflows behind the agents for one customer as a pilot on Astronomer while all other customers continued running on Composer. We used a 48-hour validation window covering end-to-end DAG runs and downstream data quality checks.
For one customer’s export pipeline, we ran Astronomer in shadow mode before switching over. That meant processing real data in parallel, comparing outputs, and validating behavior before committing production traffic.
We also kept a rollback path ready. If anything looked wrong, we could re-trigger on Composer, investigate, and delay the move.
The goal was not just to prove that Astronomer could run the workflows. The goal was to prove that our team could operate those workflows without introducing new failure modes.
What changed after the migration
The most concrete metric was worker eviction failures.
On Cloud Composer, we typically saw 0 to 10 worker eviction failures per week. Someone on call would get paged, manually retry the failed DAGs, and the DAGs would complete.
On Astronomer, that category of failure is effectively gone.
The other improvements compounded quickly.
Area | Before | After |
Worker evictions | 0 to 10 failures per week | Effectively zero |
Local setup | Several hours | Under five minutes |
Worker capacity | Standing pool sized for peak | Queues scale from zero |
High-memory tasks | Shared workers, higher OOM risk | Isolated high-memory queue |
Alerts | Custom Slack alerting | Native Astronomer alerts |
Infrastructure setup | Manual or partially documented | Terraform-managed |
The impact was not only cost reduction. It changed the team’s operating model.
Engineers can set up local development quickly. Airflow upgrades are no longer something we avoid by default. Alerts are cleaner. Infrastructure is easier to reproduce and audit. Worker capacity now matches the shape of the work instead of the worst-case scenario.
That gives the engineering team more time to focus on the systems that make Aampe work for customers.
When to stay and when to move
This story should not be read as “everyone should leave Composer.” Composer may be the right choice for many teams.
The better question is whether your infrastructure is still serving your team or whether your team has started serving the infrastructure.
Look for behavior changes.
Are engineers avoiding upgrades because they do not trust the process? Are on-call rotations dealing with transient infrastructure failures that have nothing to do with the data? Are teams over-provisioning because autoscaling is unpredictable? Does local development take long enough that it slows down every new change? Are manual retries treated as normal?
Each issue might be tolerable in isolation. Together, they can cost more than a migration.
Most teams stay too long with infrastructure that no longer fits because they never measure the operational tax directly. We did the math, and for us, moving was cheaper than continuing to normalize the friction.
What we would do differently next time
We would run shadow mode for every customer, not just one. The confidence it provides is worth the extra setup time.
We would also start decoupling from cloud-native dependencies earlier. The move to Airflow-native hooks was the right decision, but it would have been easier as a gradual portability effort rather than part of the migration itself.
For any team running Composer at scale, that work is worth starting before you need it.
The Real Cost of Staying
We contacted Astronomer support twice during a migration of more than 600 workflows.
The migration still required real engineering work. But the work was bounded, testable, and visible. The cost of staying on Composer had become harder to see because it showed up as avoided upgrades, idle workers, noisy retries, and developer time lost to workarounds.
Infrastructure friction becomes expensive when it changes team behavior.
Once that happens, the switching cost may already be lower than the cost of staying.
Why this matters beyond infrastructure
This was an Airflow migration, but the lesson is broader.
At Aampe, we help marketing, growth, and product teams move away from brittle campaign rules and toward customer engagement systems that adapt based on user behavior. That kind of product requires engineering systems with the same bias toward reliability, feedback, and adaptability.
If customer-facing systems are supposed to learn and adapt, the infrastructure behind them cannot depend on constant manual intervention. If our product promise depends on orchestrating decisions and workflows at scale, our internal systems need to give engineers clarity, control, and short feedback loops.
The Composer migration was one example of that principle in practice.
We saw friction. We measured it. We compared the cost of staying with the cost of moving. Then we redesigned the system around the actual shape of the work.
That is the same kind of thinking we bring to customer engagement. The goal is not to add more rules, more manual oversight, or more workarounds. The goal is to build systems that learn from what is happening, adapt as conditions change, and reduce unnecessary human effort over time.
If you’re interested in seeing some of these principles come to fruition in Aampe’s live product, book a demo with our team here.